Automatische Erfassung einer Preisliste
1 PDF, 83 Seiten, 4 Spalten, 23 Zeilen, somit ca 7.638 Preise. Wer eine solche Preisliste händisch von Euro- zu Dollarpreisen mit Aufschlag umwandeln muss, der wird eher wenig begeistert sein.
Am einfachsten wäre es ja, die Originaldatei heranzuziehen, die Preise darin zu ändern und eine neue PDF auszugeben. Doch das Original stand nicht zur Verfügung.
Also in Acrobat Pro 7.638 mal klicken, den Preis markieren, in den Rechner kopieren, multiplizieren, Ergebnis zurück kopieren, Eurozeichen löschen, Dollarzeichen hinzufügen? Wenn dieser Vorgang auch nur 10 Sekunden braucht, wäre man bereits 21 Stunden am Stück beschäftigt. Langweilig.
Ich wollte das Problem schneller und intelligenter lösen. Zunächst versuchte ich, die Preise direkt in der PDF zu ersetzen. Mir war bewusst, dass dies keine hohen Erfolgschancen hatte, da das PDF-Format notorisch schwierig zu bearbeiten ist. Und tatsächlich scheiterte ich am Wiedereinfügen der veränderten Daten. (Über diesbezügliche Tipps würde ich mich freuen!)
Also musste eine Notlösung her. Wenn ich schon nicht den gesamten Prozess automatisieren konnte, so wollte ich doch zumindest eine Arbeitshilfe schaffen. Ich programmierte also ein Autohotkey-Skript, das mit Alt+C den markierten Text automatisch mit RegEx erfasst, konvertiert und wieder einfügt. Somit musste man in Acrobat Pro nur noch auf die einzelnen Textfelder klicken und dann Alt+C drücken.
Doch wirklich zufrieden war ich damit nicht. Auch 7.638 maliges Klicken ist langweilig.
Ich schrieb daher ein Pythonskript, das die Seiten der PDF zunächst als einzelne Bilder speichert. Dann wird ein Bild nach dem anderen geladen und mit OpenCV aufbereitet (grayscale, adaptive Threshold, erode/dilate, denoise). Das Programm sucht dann nach Konturen, die den Kästchen auf der Preisliste entsprechen und extrahiert diese.
Dann werden diese Bilder der Preise an Tesseract weitergegeben, um den Text zu erkennen. Leider war die Erkennung zunächst sehr unzuverlässig, da die Schriftart manche Ziffern sehr eigentümlich darstellt. Ich hätte Tesseract mit der Schriftart trainieren können, was wahrscheinlich die besten Resultate geliefert hätte, doch dafür war keine Zeit. Durch Trial und Error fand ich letztlich eine Kombination aus Erosion und Dilation, die den Text für Tesseract erkennbar machte.
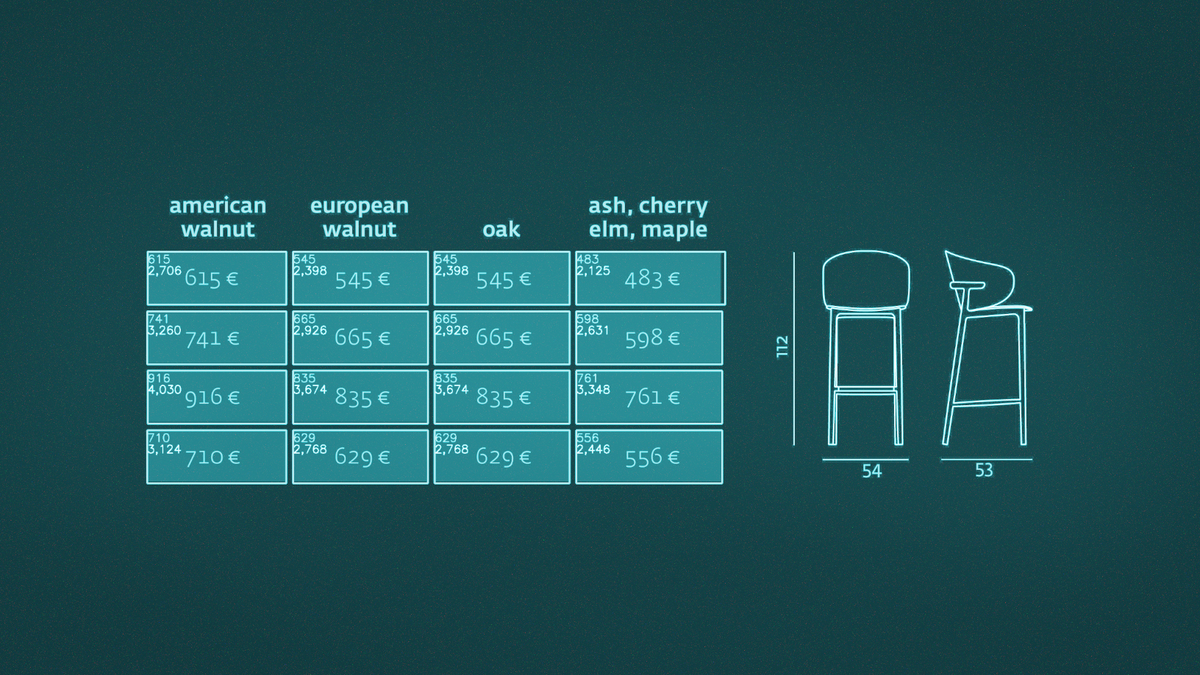
Nun konnte ich die Textboxen einfach mit der Hintergrundfarbe überzeichnen und mit der gleichen Schriftart den Dollarpreis darüberschreiben.
Die Lösung war nicht perfekt, da OCR immer fehleranfällig sein wird, doch lag sie nun wahrscheinlich unter der Fehlerquote eines Menschen (der 21 Stunden das gleiche macht).
Kurz darauf bemerkte ich, dass ich mir die Bounding-Boxes der Textelemente mit der Python-Bibliothek pdfminer ausgeben lassen konnte. Also verwarf ich den OCR-Teil wieder und verwendete nun den in der PDF hinterlegten Klartext. Damit erreichte ich (logischerweise) eine Genauigkeit von 100%, was bei Preislisten von Vorteil ist.